Why Build a Starter Kit for RAG + Agents?
Let’s be honest: every developer who’s played with LLMs gets that rush of “wow” from the first working demo. But the real headaches show up when you need to stitch LLMs into something production-grade: an app that can pull in real data, coordinate multi-step logic, and more. Suddenly, you’re not just writing single prompts. You’re coordinating between multiple prompts, managing queues, adding vector databases, orchestrating workers, and trying to get things back to the user in real-time. We've found that CrewAI (coordinating prompts, agents, tools) + Django (building an api, managing data), with a bit of Celery (orchestrating workers/async tasks), is a really nice set of tools for this. We're also going to use Django Channels (real-time updates) to push updates back to the user. And of course, we'll use Defang to deploy all that to the cloud.
If this sounds familiar (or if you're dreading the prospect of dealing with it), you’re the target audience for this sample. Instead of slogging through weeks of configuration and permissions hell, you get a ready-made template that runs on your laptop, then scales—unchanged—to Defang’s Playground, and finally to your own AWS or GCP account. All the gnarly infra is abstracted, so you can focus on getting as much value as possible out of that magical combo of CrewAI and Django.
You can find it here.
A Demo in 60 Seconds
Imagine you're building a system. It might use multiple LLM calls. It might do complex, branching logic in its prompts. It might need to store embeddings to retrieve things in the future, either to pull them into a prompt, or to return them outright. It might need to store other records that don't have embeddings. Here's a very lightweight version of a system like that, as a starting point:
Architecture at a Glance
Behind the scenes, the workflow is clean and powerful. The browser connects via WebSockets to our app using Django Channels. Heavy work is pushed to a Celery worker. That worker generates an embedding, checks Postgres with pgvector for a match, and either returns the summary or, if there’s no hit, fires up a CrewAI agent to generate one. Every update streams back through Redis and Django Channels so users get progress in real time.
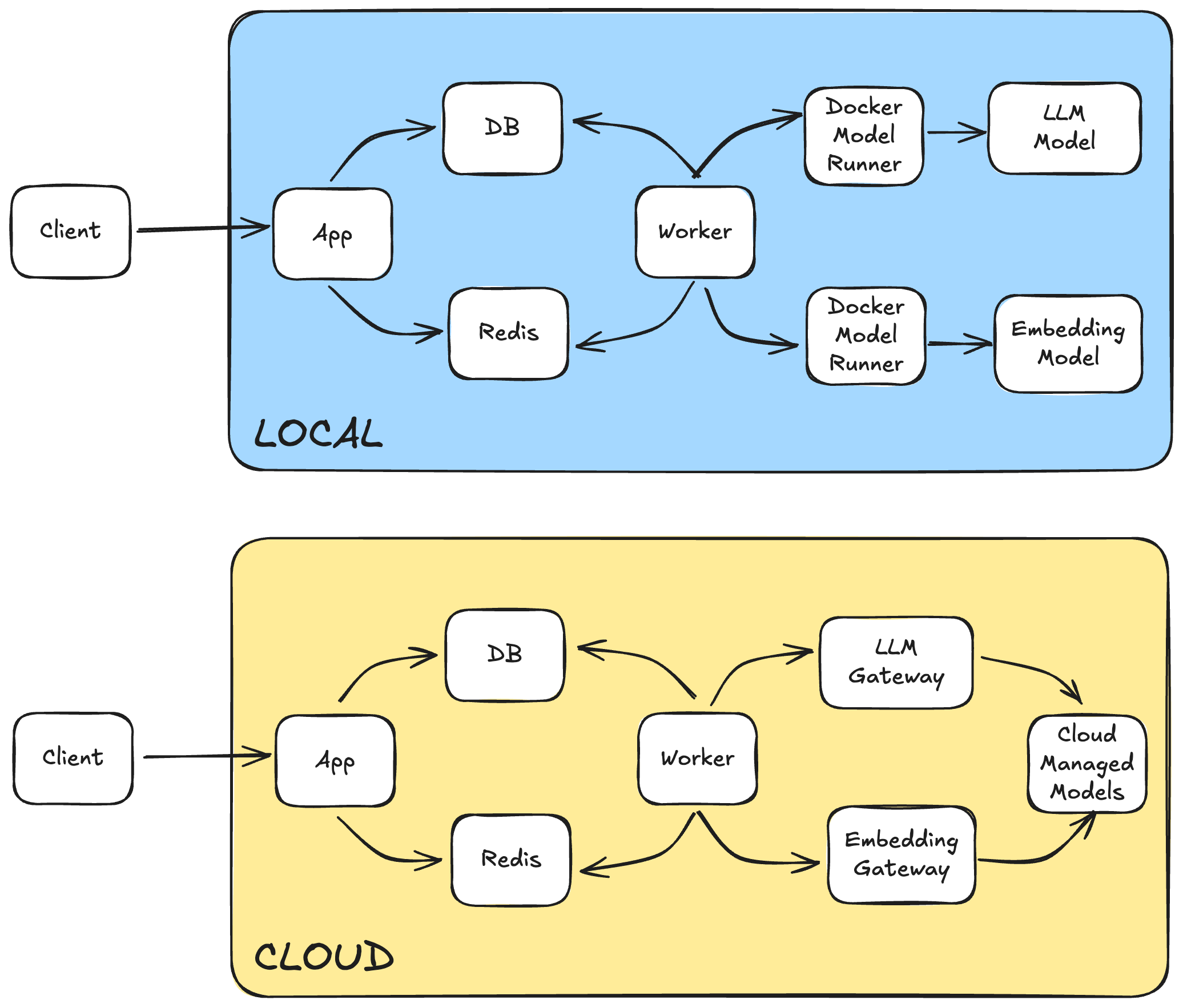
Durable state lives in Postgres and Redis. Model services (LLMs and embeddings) are fully swappable, so you can upgrade to different models in the cloud or localize with the Docker Model Runner without rewriting the full stack.
Under the Hood: The Services
Django + Channels
The Django app is the front door, routing HTTP and WebSocket traffic, serving up the admin, and delivering static content. It’s built on Daphne and Django Channels, with Redis as the channel layer for real-time group events. Django’s admin is your friend here: to start you can check what summaries exist, but if you start building out your own app, it'll make it a breeze to debug and manage your system.
PostgreSQL + pgvector
This is where your data lives. Summaries and their 1024-dimension embeddings go here. A simple SQL query checks for close matches by cosine distance, and pgvector’s index keeps search blazing fast. In BYOC (bring-your-own-cloud) mode, flip a single flag and Defang provisions you a production-grade RDS instance.
Redis
Redis is doing triple duty: as the message broker and result backend for Celery, and as the channel layer for real-time WebSocket updates. The pub/sub system lets a single worker update all browser tabs listening to the same group. And if you want to scale up, swap a flag and Defang will run managed ElastiCache in production. No code change required.
Celery Worker
The Celery worker is where the magic happens. It takes requests off the queue, generates embeddings, checks for similar summaries, and—if necessary—invokes a CrewAI agent to get a new summary. It then persists summaries and pushes progress updates back to the user.
LLM and Embedding Services
Thanks to Docker Model Runner, the LLM and embedding services run as containerized, OpenAI-compatible HTTP endpoints. Want to switch to a different model? Change a single line in your compose file. Environment variables like LLM_URL and EMBEDDING_MODEL are injected for you—no secret sharing or hard-coding required.
CrewAI Workflows
With CrewAI, your agent logic is declarative and pluggable. This sample keeps it simple—a single summarization agent—but you can add classification, tool-calling, or chain-of-thought logic without rewriting your task runner.
How the Compose Files Work
In local dev, your compose.local.yaml spins up Gemma and Mixedbread models, running fully locally and with no cloud credentials or API keys required. URLs for service-to-service communication are injected at runtime. When you’re ready to deploy, swap in the main compose.yaml which adds Defang’s x-defang-llm, x-defang-redis, and x-defang-postgres flags. Now, Defang maps your Compose intent to real infrastructure—managed model endpoints, Redis, and Postgres—on cloud providers like AWS or GCP. It handles all networking, secrets, and service discovery for you. There’s no YAML rewriting or “dev vs prod” drift.
The Three-Step Deployment Journey
You can run everything on your laptop with a single docker compose -f ./compose.local.yaml up command—no cloud dependencies, fast iteration, and no risk of cloud charges. When you’re ready for the next step, use defang compose up to push to the Defang Playground. This free hosted sandbox is perfect for trying Defang, demos, or prototyping. It automatically adds TLS to your endpoints and sleeps after a week. For production, use your own AWS or GCP account. DEFANG_PROVIDER=aws defang compose up maps each service to a managed equivalent (ECS, RDS, ElastiCache, Bedrock models), wires up secrets, networking, etc. Your infra. Your data.
Some Best Practices and Design Choices
This sample uses vector similarity to try and fetch summaries that are semantically similar to the input. For more robust results, you might want to embed the original input. You can also think about chunking up longer content for finer-grained matches that you can integrate in your CrewAI workflows. Real-time progress via Django Channels beats HTTP polling, especially for LLM tasks that can take a while. The app service is stateless, which means you can scale it horizontally just by adding more containers which is easy to specify in your compose file.
Going Further: Extending the Sample
You’re not limited to a single summarization agent. CrewAI makes it trivial to add multi-agent flows (classification, tool use, knowledge retrieval). For big docs, chunk-level embeddings allow granular retrieval. You can wire in tool-calling to connect with external APIs or databases. You can integrate more deeply with Django's ORM and the PGVector tooling that we demo'd in the sample to build more complex agents that actually use RAG.
Ready to Build?
With this sample, you’ve got an agent-ready, RAG-ready backend that runs anywhere, with no stacks of YAML or vendor lock-in. Fork it, extend it, productionize it: scale up, add more agents, or swap in different models, or more models!
Quickstart:
# Local
docker compose -f compose.local.yaml up --build
# Playground
defang compose up
# BYOC
# Setup credentials and then swap <provider> with aws or gcp
DEFANG_PROVIDER=<provider> defang compose up
Want more? File an issue to request a sample—we'll do everything we can to help you deploy better and faster!