August was about making migrations smoother and showing how you can already use Defang to deploy agentic apps at scale. We expanded our sample projects for popular multi-agent frameworks like CrewAI, LangGraph, Autogen, and Strands, validating them on Playground, AWS, and GCP so you can run multi-agent workloads in production without extra DevOps. Our new Heroku migration flow inspects dynos and add-ons, generates a clean Compose file, provisions managed equivalents like Postgres and Redis, and ships to your own cloud in one command. This cuts costs and removes lock-in. We also introduced MCP BYOC prompts so you can deploy to AWS and GCP straight from your IDE. Railpack on GCP now delivers faster, more reliable no-Dockerfile builds with clearer logs and closer parity with AWS.
As more and more teams are moving away from legacy PaaS solutions, looking for more flexibility and more control, we’ve made it easier for teams to move off Heroku. Defang now supports deployments without a Dockerfile and Defang will even generate a compose file from your Heroku application. The result is a smoother path to AWS or GCP with more features, lower costs, and no lock-in.
We expanded and refined our sample projects for agentic frameworks like CrewAI, LangGraph, Autogen, and Strands, validating across Playground, AWS, and GCP for a seamless move to production. Agentic applications demand more than code. They need scalable compute, managed databases and caches, security, orchestration, and LLM integrations. That’s why Defang automates all the heavy lifting. When you define your app once in Docker Compose, Defang handles provisioning on AWS or GCP including compute, managed Postgres or MongoDB, Redis, LLM services, security, auto scaling, and compliance so you can focus purely on your agents.
We now support deploying to AWS and GCP through the Defang MCP Server using prompts in your IDE. This keeps your workflow fast and frictionless, letting you go from code to cloud in seconds without breaking focus. You can stay in the flow with no context switching, spinning up services or scaling workloads simply by chatting in your editor. It means faster iteration, shorter feedback loops, and less time wrestling with terminals or cloud consoles.
Railpack now works more smoothly on GCP with fixes to image builds, provider consistency, and a redesigned repo. You’ll see faster first builds and rebuilds with better caching, clearer logs when something fails, and closer parity with AWS so templates behave the same across clouds. Railpack also auto-detects common stacks when no Dockerfile is present, applies sensible defaults for runtime, ports, and health checks, and produces clean OCI images for Playground or your own cloud. Net result: you can ship no-Dockerfile apps across clouds with less setup and fewer surprises.
In August, one of our campus advocates, Swapnendu Banerjee, hosted a session that showed how quickly you can deploy real apps to the cloud with Defang. Looking ahead, we’ll be at the ALL IN conference in Montreal this month and would love to connect if you’re a Defang user or planning to attend.
We are excited to see what you will deploy with Defang next. Join our Discord to ask questions, get support, and share your builds with the community.
July was all about making cloud deployments even smoother and smarter. We focused on removing friction from deployments and giving you better visibility into costs. Railpack now builds production-ready images automatically when no Dockerfile is present, and our real-time cost estimation feature now supports Google Cloud alongside AWS. We also added managed MongoDB on GCP, introduced an Agentic LangGraph sample, and connected with builders at Bière & Code & Beer MTL. Here’s what’s new.
We’ve integrated Railpack into Defang to make deployments even smoother. Railpack automatically builds OCI-compliant images from your source code with minimal configuration. This helps eliminate one of the most common issues our users face: missing or invalid Dockerfiles, especially when they’re generated by LLMs or created by users with limited Docker experience. Now, if no Dockerfile is provided, Defang will seamlessly use Railpack to build a working image for you, so you can focus on your code, not your container setup.
In June, Defang announced real-time cost estimation for AWS. In July, we took our live cloud cost estimation to the next level by extending support to GCP. Defang now makes it easy to compare real-time pricing for both cloud providers. All you need is your project's compose.yaml file. Whether you’re optimizing for cost, performance, or flexibility, Defang makes it easy to get the information you need to deploy with confidence.
Defang now supports managed MongoDB on GCP through MongoDB-compatible APIs provided by Google Cloud. This integration allows you to spin up a fully managed Firestore datastore and interact with it just like a standard MongoDB instance without any manual setup or configuration.
We have published a new Agentic LangGraph sample project that demonstrates LangGraph agent deployment with Defang. As AI agent development grows, Defang makes it simple to deploy and scale agents, including those built with LangChain or LangGraph. You can explore the example to see how it works in practice.
In July, we hosted the Bière & Code & Beer MTL during Startupfest in Montreal. It was an incredible evening with great energy, tech conversations, and the chance to connect with so many talented builders over drinks.
We are excited to see what you will deploy with Defang next. Join our Discord to ask questions, get support, and share your builds with the community.
From Vibe-Coding to Production… Without a DevOps Team
Building apps has never been easier. Tools like Cursor, Windsurf, Lovable, V0, and Bolt have ushered in a new era of coding called vibe coding, rapid, AI-assisted app development where developers can go from idea to prototype in hours, bringing ideas to life faster than ever before.
And with the recently released AWS Kiro, we have now entered a new phase of AI-assisted development called "spec-driven development" where the AI breaks down the app development task even further. You can think of a "PM agent" that goes from prompt to a requirements document, and then an "Architect agent" that goes from the requirements document to a design document, which is then used by "Dev", "Test" and "Docs" agents to generate app code, tests, and documentation respectively. This approach is much more aligned with enterprise use cases and produces higher quality output.
However, cloud app deployment remains a major challenge! As Andrej Karpathy shared during his recent YC talk:
"I vibe-coded the app in four hours… and spent the rest of the week deploying it."
While AI-powered tools make building apps a breeze, deploying them to the cloud is still frustratingly complex. Kubernetes, Terraform, IAM policies, load balancers, DNS, CI/CD all add layers of difficulty. This complexity continues to be a significant bottleneck that AI tools have yet to fully address, making deployment a critical challenge for developers.
The bottleneck is no longer the code. It's the infrastructure.
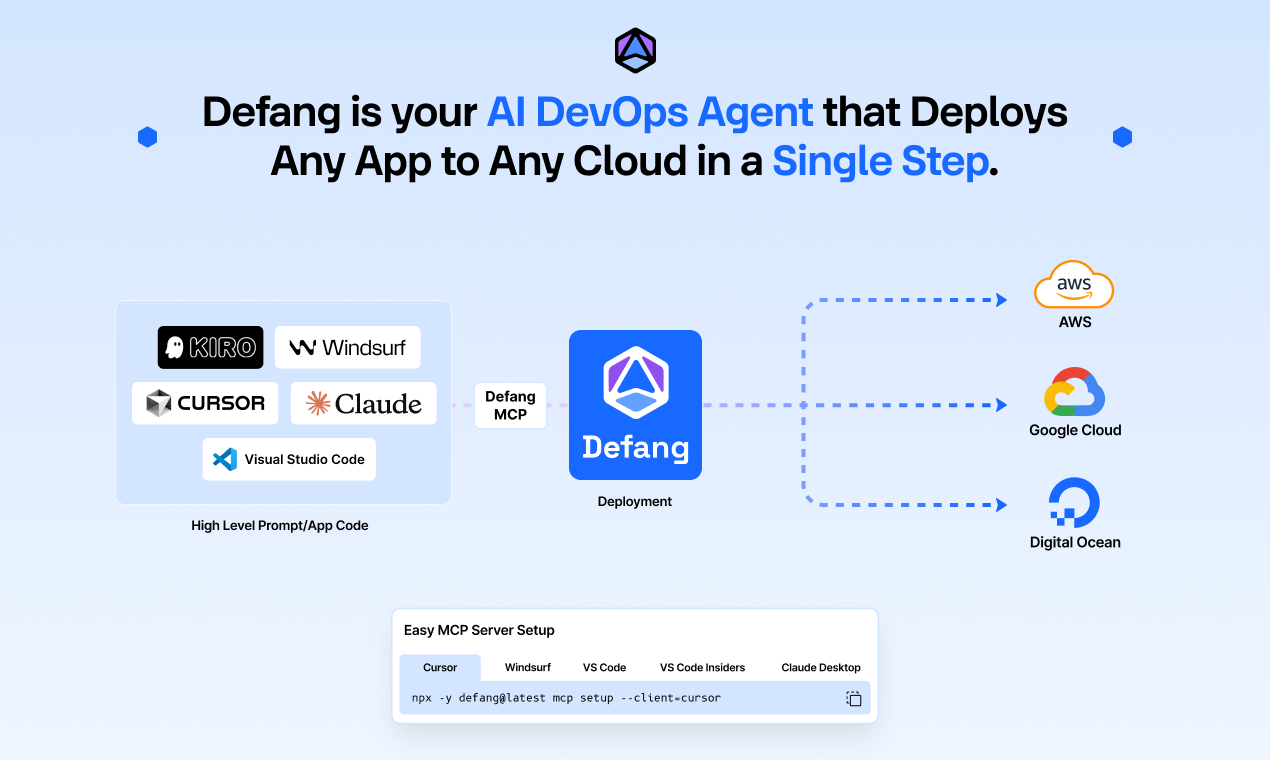
Defang is an AI-enabled agent that takes care of your entire deployment workflow, going from app code to a production-ready deployment on your favorite cloud in a single step.
By understanding your app stack (using Docker Compose), Defang provisions the right infrastructure and securely deploys to AWS, GCP, or DigitalOcean, following each cloud's best practices.
Whether you're launching a side project or scaling a multi-agent app, Defang ensures secure, smooth, scalable cloud-native deployments.
One Command Deployment: Run defang compose up and you're live
Secure and Scalable: Built-in TLS, secrets, autoscaling, IAM, and HTTPS
Multi-Cloud Ready: Deploy to your cloud (AWS, GCP, DO) using your own credentials
Language & framework agnostic: Next.js, Go, Python (Django/Flask), C#, …
Managed LLM: Add x-defang-llm: true and Defang auto-configures cloud-native LLMs like Bedrock, Vertex AI, and the Defang Playground
Configures managed services (e.g. managed Postgres, MongoDB, Redis) using the target cloud's native services (e.g. RDS for Postgres on AWS, Cloud SQL on GCP).
Tailored deployment modes (e.g. affordable, balance, high-availability) optimized for different environments (dev, staging, production)
AI Debugging: Get context-aware assistance to quickly identify and fix deployment issues
Defang can be accessed directly from within your favorite IDE - Cursor, Windsurf, VS Code, Claude, or Kiro - via Defang's MCP Server. You can now deploy to the cloud with a natural language command like "deploy my app with Defang".
June was a big month at Defang. We rolled out powerful features across our CLI, Playground, and Portal, expanded support for both AWS and GCP, and introduced new tools to help you ship faster and smarter. From real-time cloud cost estimation to internal infra upgrades and community highlights, here’s everything we accomplished.
We just launched something we’re really excited about: live AWS cost estimation before you deploy.
Most devs ship to the cloud without knowing what it’s going to cost and that’s exactly the problem we’re solving. With Defang, you can now estimate the cost of deployment of an Docker Compose application and choose the deployment mode - affordable / balanced / high_availability - that best suits your needs.
In June, we launched a full-stack starter kit for building real-time RAG and multi-agent apps with CrewAI + Defang.
It’s designed to help you move fast with a production-style setup — including Django, Celery, Channels, Postgres (with pgvector), Redis for live updates, and Dockerized model runners you can easily customize. CrewAI handles the agent workflows, and with Defang, you can deploy the whole thing to the cloud in a single command.
Whether you’re building a smart Q&A tool or a multi-agent research assistant, this stack gives you everything you need to get started.
We’ve added active deployment information to the Defang Portal. You can now see your currently active deployments across various cloud providers and understand the details of each, while still managing your cloud environments through the provider’s own tools (e.g. the AWS Console).
Internally, we also hit a big milestone: The Defang Playground now runs on both AWS and GCP, showing the power of Defang’s multi-cloud infrastructure. We’ve also enabled load balancing between the two platforms and plan to share a detailed blog post on how it works soon.
You can now try out the Ask Defang chatbot directly within Intercom! This new integration makes it easier than ever to get instant answers and support while you work. Ask Defang itself is deployed using Defang to our own cloud infrastructure.
And one more thing: bridging local development and cloud deployment just got easier. We’ve published white papers on how Defang extends Docker Compose and GCP workflows to the cloud — using familiar tools at scale. An AWS white paper is coming soon.
In June, we showcased a powerful new demo at AWS events: “What If You Could See AWS Costs Before You Deployed?” Jordan Stephens walked through how to go from Docker Compose to AWS infra with real-time cost estimates and easy teardown, all via Defang.
Let’s be honest: every developer who’s played with LLMs gets that rush of “wow” from the first working demo. But the real headaches show up when you need to stitch LLMs into something production-grade: an app that can pull in real data, coordinate multi-step logic, and more. Suddenly, you’re not just writing single prompts. You’re coordinating between multiple prompts, managing queues, adding vector databases, orchestrating workers, and trying to get things back to the user in real-time. We've found that CrewAI (coordinating prompts, agents, tools) + Django (building an api, managing data), with a bit of Celery (orchestrating workers/async tasks), is a really nice set of tools for this. We're also going to use Django Channels (real-time updates) to push updates back to the user. And of course, we'll use Defang to deploy all that to the cloud.
If this sounds familiar (or if you're dreading the prospect of dealing with it), you’re the target audience for this sample. Instead of slogging through weeks of configuration and permissions hell, you get a ready-made template that runs on your laptop, then scales—unchanged—to Defang’s Playground, and finally to your own AWS or GCP account. All the gnarly infra is abstracted, so you can focus on getting as much value as possible out of that magical combo of CrewAI and Django.
Imagine you're building a system. It might use multiple LLM calls. It might do complex, branching logic in its prompts. It might need to store embeddings to retrieve things in the future, either to pull them into a prompt, or to return them outright. It might need to store other records that don't have embeddings. Here's a very lightweight version of a system like that, as a starting point:
Behind the scenes, the workflow is clean and powerful. The browser connects via WebSockets to our app using Django Channels. Heavy work is pushed to a Celery worker. That worker generates an embedding, checks Postgres with pgvector for a match, and either returns the summary or, if there’s no hit, fires up a CrewAI agent to generate one. Every update streams back through Redis and Django Channels so users get progress in real time.
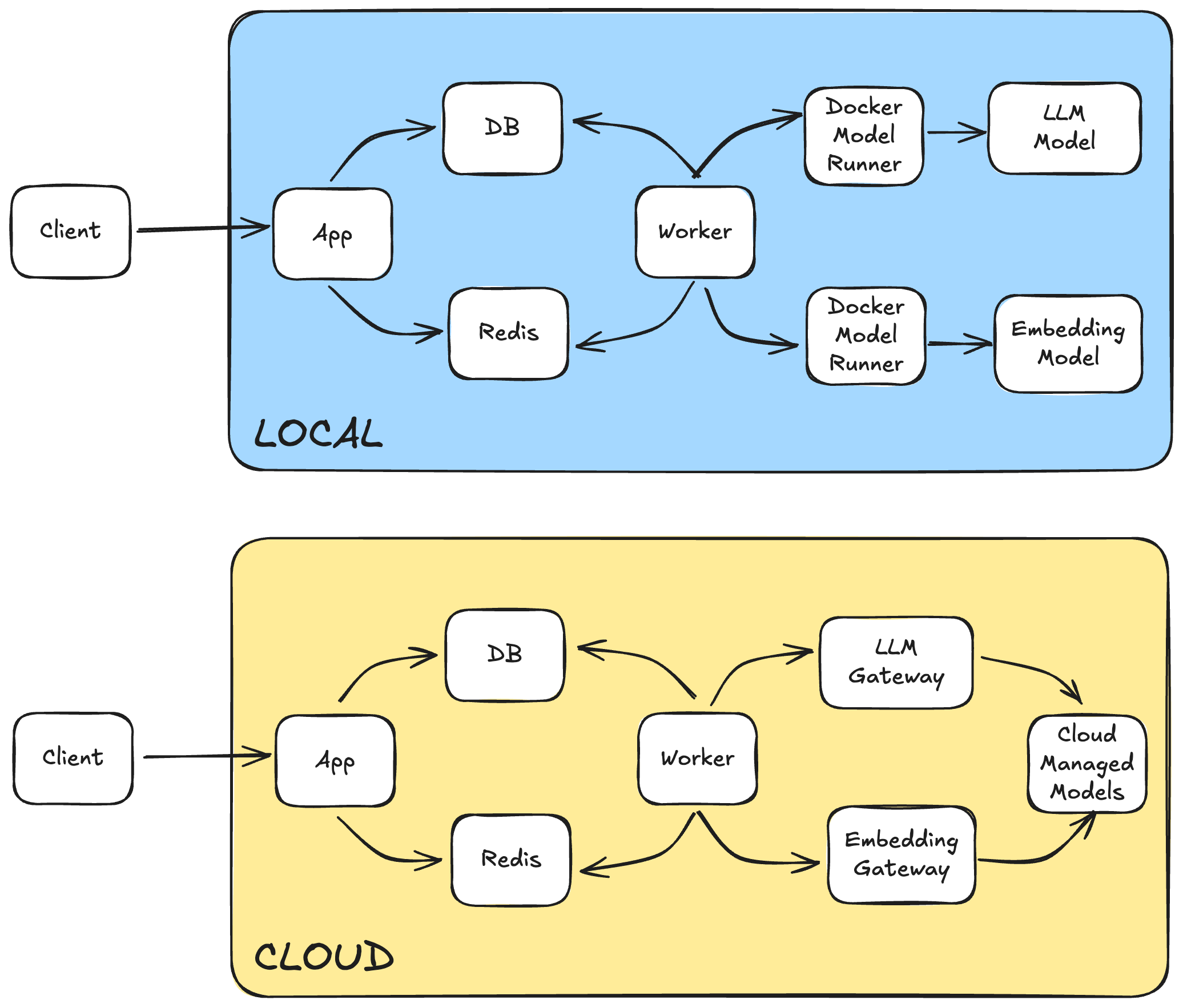
Durable state lives in Postgres and Redis. Model services (LLMs and embeddings) are fully swappable, so you can upgrade to different models in the cloud or localize with the Docker Model Runner without rewriting the full stack.
The Django app is the front door, routing HTTP and WebSocket traffic, serving up the admin, and delivering static content. It’s built on Daphne and Django Channels, with Redis as the channel layer for real-time group events. Django’s admin is your friend here: to start you can check what summaries exist, but if you start building out your own app, it'll make it a breeze to debug and manage your system.
This is where your data lives. Summaries and their 1024-dimension embeddings go here. A simple SQL query checks for close matches by cosine distance, and pgvector’s index keeps search blazing fast. In BYOC (bring-your-own-cloud) mode, flip a single flag and Defang provisions you a production-grade RDS instance.
Redis is doing triple duty: as the message broker and result backend for Celery, and as the channel layer for real-time WebSocket updates. The pub/sub system lets a single worker update all browser tabs listening to the same group. And if you want to scale up, swap a flag and Defang will run managed ElastiCache in production. No code change required.
The Celery worker is where the magic happens. It takes requests off the queue, generates embeddings, checks for similar summaries, and—if necessary—invokes a CrewAI agent to get a new summary. It then persists summaries and pushes progress updates back to the user.
Thanks to Docker Model Runner, the LLM and embedding services run as containerized, OpenAI-compatible HTTP endpoints. Want to switch to a different model? Change a single line in your compose file. Environment variables like LLM_URL and EMBEDDING_MODEL are injected for you—no secret sharing or hard-coding required.
With CrewAI, your agent logic is declarative and pluggable. This sample keeps it simple—a single summarization agent—but you can add classification, tool-calling, or chain-of-thought logic without rewriting your task runner.
In local dev, your compose.local.yaml spins up Gemma and Mixedbread models, running fully locally and with no cloud credentials or API keys required. URLs for service-to-service communication are injected at runtime. When you’re ready to deploy, swap in the main compose.yaml which adds Defang’s x-defang-llm, x-defang-redis, and x-defang-postgres flags. Now, Defang maps your Compose intent to real infrastructure—managed model endpoints, Redis, and Postgres—on cloud providers like AWS or GCP. It handles all networking, secrets, and service discovery for you. There’s no YAML rewriting or “dev vs prod” drift.
You can run everything on your laptop with a single docker compose -f ./compose.local.yaml up command—no cloud dependencies, fast iteration, and no risk of cloud charges. When you’re ready for the next step, use defang compose up to push to the Defang Playground. This free hosted sandbox is perfect for trying Defang, demos, or prototyping. It automatically adds TLS to your endpoints and sleeps after a week. For production, use your own AWS or GCP account. DEFANG_PROVIDER=aws defang compose up maps each service to a managed equivalent (ECS, RDS, ElastiCache, Bedrock models), wires up secrets, networking, etc. Your infra. Your data.
This sample uses vector similarity to try and fetch summaries that are semantically similar to the input. For more robust results, you might want to embed the original input. You can also think about chunking up longer content for finer-grained matches that you can integrate in your CrewAI workflows. Real-time progress via Django Channels beats HTTP polling, especially for LLM tasks that can take a while. The app service is stateless, which means you can scale it horizontally just by adding more containers which is easy to specify in your compose file.
You’re not limited to a single summarization agent. CrewAI makes it trivial to add multi-agent flows (classification, tool use, knowledge retrieval). For big docs, chunk-level embeddings allow granular retrieval. You can wire in tool-calling to connect with external APIs or databases. You can integrate more deeply with Django's ORM and the PGVector tooling that we demo'd in the sample to build more complex agents that actually use RAG.
With this sample, you’ve got an agent-ready, RAG-ready backend that runs anywhere, with no stacks of YAML or vendor lock-in. Fork it, extend it, productionize it: scale up, add more agents, or swap in different models, or more models!
Quickstart:
# Local docker compose -f compose.local.yaml up --build # Playground defang compose up # BYOC # Setup credentials and then swap <provider> with aws or gcp DEFANG_PROVIDER=<provider> defang compose up
Want more? File an issue to request a sample—we'll do everything we can to help you deploy better and faster!
Modern software development moves fast, but deploying to the cloud often remains a complex hurdle. Docker Compose revolutionized local development by providing a simple way to define multi-service apps, but translating that simplicity into cloud deployment has remained challenging—until now.
Defang bridges this gap by extending Docker Compose into native cloud deployments across AWS, GCP, DigitalOcean, and more, all with a single command: defang compose up. This integration empowers developers to:
Use familiar Docker Compose definitions for cloud deployment.
Enjoy seamless transitions from local to multi-cloud environments.
Automate complex infrastructure setups including DNS, networking, autoscaling, managed storage, and even managed LLMs.
Estimate cloud costs and choose optimal deployment strategies (affordable, balanced, or high availability).
Our whitepaper dives deep into how Docker Compose paired with Defang significantly reduces complexity, streamlines workflows, and accelerates development and deployment.
Discover how Docker + Defang can simplify your journey from local development to production-ready deployments across your preferred cloud providers.
May was a big month at Defang. We shipped support for managed LLMs in Playground, added MongoDB support on AWS, improved the Defang MCP Server, and dropped new AI samples to make deploying faster than ever.
You can now try managed LLMs directly in the Defang Playground.
Defang makes it easy to use cloud-native language models across providers — and now you can test them instantly in the Playground.
Managed LLM support
Playground-ready
Available in CLI v1.1.22 or higher
To use managed language models in your own Defang services, just add x-defang-llm: true — Defang will configure the appropriate roles and permissions for you.
Already built on the OpenAI API? No need to rewrite anything.
With Defang's OpenAI Access Gateway, you can run your existing apps on Claude, DeepSeek, Mistral, and more — using the same OpenAI format.
April flew by with big momentum at Defang. From deeper investments in the Model Context Protocol (MCP), to deploying LLM-based inferencing apps, to live demos of Vibe Deploying, we're making it easier than ever to go from idea to cloud.
This month we focused on making cloud deployments as easy as writing a prompt. Our latest Vibe Deploying blog shows how you can launch full-stack apps right from your IDE just by chatting.
Whether you're working in Cursor, Windsurf, VS Code, or Claude, Defang's MCP integration lets you deploy to the cloud just as easily as conversing with the AI to generate your app. For more details, check out the docs for the Defang Model Context Protocol Server – it explains how it works, how to use it, and why it's a game changer for deploying to the cloud. You can also watch our tutorials for Cursor, Windsurf, and VS Code.
Last month we shipped the x-defang-llm compose service extension to easily deploy inferencing apps that use managed LLM services such as AWS Bedrock. This month, we're excited to announce the same support for GCP Vertex AI – give it a try and let us know your feedback!
On April 28, we kicked things off with an epic night of demos, dev energy, and cloud magic at RAG & AI in Action. Our own Kevin Vo showed how fast and easy it is to deploy AI apps from Windsurf to the cloud using just the Defang MCP. The crowd got a front-row look at how Vibe Deploying turns cloud infra into a background detail.
We finished the month with our signature Defang Coffee Chat, a casual hangout with product updates, live Q&A, and great conversations with our community. Our Campus Advocates also hosted workshops around the world, bringing Defang to new students and builders.
We wrapped up the month with our latest Defang Coffee Chat, featuring live demos, product updates, and a solid conversation around vibe deploying. Thanks to everyone who joined.
The next one is on May 21 at 10 AM PST. Save your spot here.
Welcome to the world of vibe coding, an AI-assisted, intuition-driven way of building software. You do not spend hours reading diffs, organizing files, or hunting through documentation. You describe what you want, let the AI take a pass, and keep iterating until it works.
The Tools of Vibe Coding
Vibe coding would not exist without a new generation of AI-first tools. Here are some of the platforms powering this new workflow.
Defang takes your app, as specified in your docker-compose.yml, and deploys it to the public cloud (AWS, GCP, or DigitalOcean) or the Defang Playground with a single command. It is already used by thousands of developers around the world to deploy their projects to the cloud.
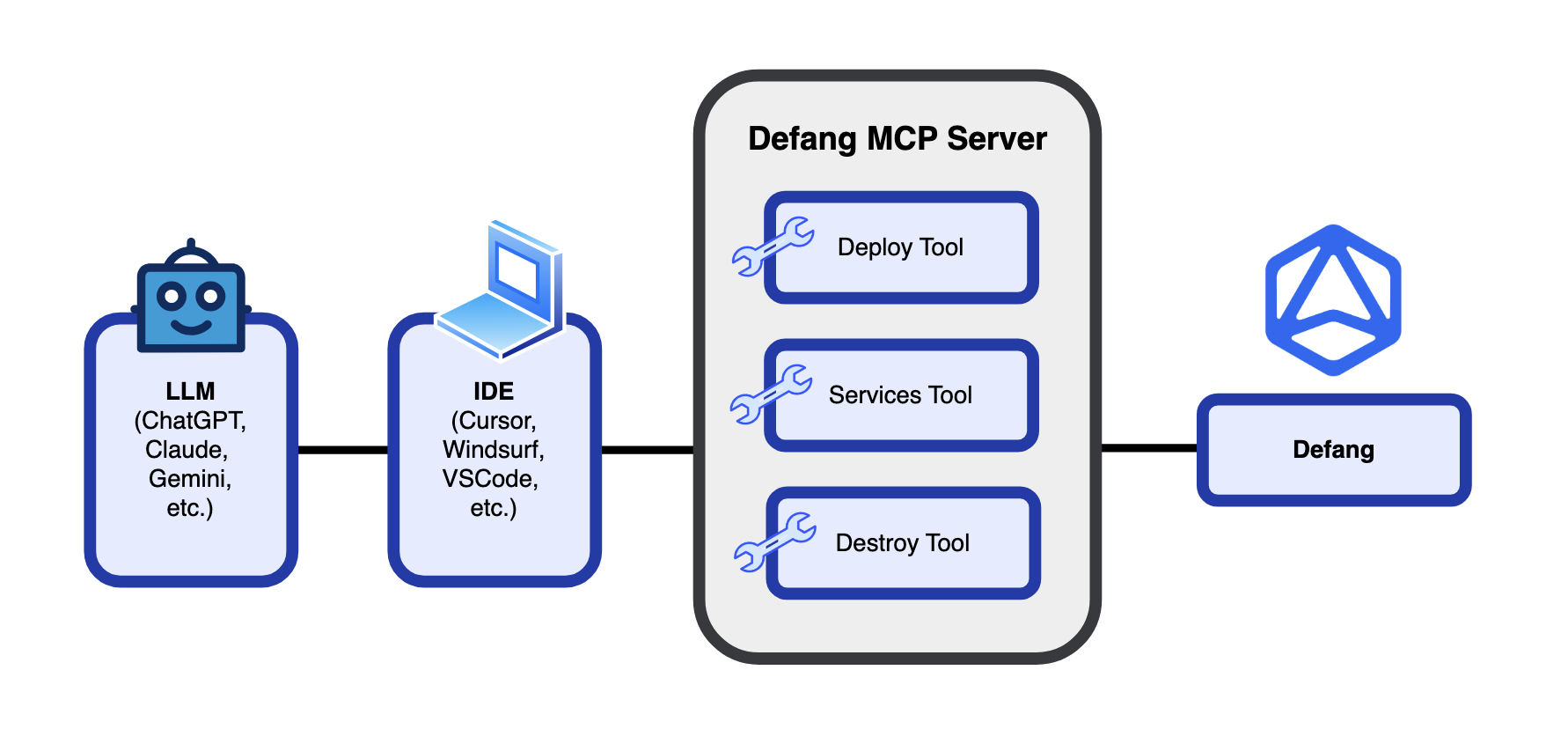
And now with the Defang MCP Server, you can "vibe deploy" your project right from your favorite IDE! Once you have the Defang MCP Server installed (see instructions here), just type in "deploy" (or any variation thereof) in the chat, it's that simple! It is built for hobbyists, vibe coders, fast-moving teams, and AI-powered workflows.
Currently, we support deployment to the Defang Playground only, but we'll be adding deployment to public cloud soon.
How it works:
The Defang MCP Server connects your coding editor (like VS Code or Cursor) with Defang's cloud tools, so you can ask your AI assistant to deploy your project just by typing a prompt. While natural language commands are by nature imprecise, the AI in your IDE translates that natural language prompt to a precise Defang command needed to deploy your application to the cloud. And your application also has a formal definition - the compose.yaml file - either something you wrote or the AI generated for you. So, the combination of a formal compose.yaml with a precise Defang command means that the resulting deployment is 100% deterministic and reliable. So the Defang MCP Server gives you the best of both worlds - the ease of use and convenience of natural language interaction with the AI, combined with the predictability and reliability of a deterministic deployment.
We are so excited to make Defang even more easy to use and accessible now to vibe coders. Give it a try and let us know what you think on our Discord!
Defang Pulumi Provider: Last month, we announced a preview of the Defang Pulumi Provider, and this month we are excited to announce that V1 is now available in the Pulumi Registry. As much as we love Docker, we realize there are many real-world apps that have components that (currently) cannot be described completely in a Compose file. With the Defang Pulumi Provider, you can now leverage the declarative simplicity of Defang with the imperative power of Pulumi.
Production-readiness: As we onboard more customers, we are fixing many fit-n-finish items:
Autoscaling: Production apps need the ability to easily scale up and down with load, and so we've added support for autoscaling. By adding the x-defang-autoscaling: true extension to your service definition in Compose.yaml file, you can benefit from automatic scale out to handle large loads and scale in when load is low. Learn more here.
NewCLI: We've been busy making the CLI more powerful, secure, and intelligent.
• Smarter Config Handling: The new --random flag simplifies setup by generating secure, random config values, removing the need for manual secret creation. Separately, automatic detection of sensitive data in Compose files helps prevent accidental leaks by warning you before they are deployed. Together, these features improve security and streamline your workflow.
• Time-Bound Log Tailing: Need to investigate a specific window? Use tail --until to view logs up to a chosen time—no more scrolling endlessly. Save time from sifting through irrelevant events and focus your investigation.
• Automatic generation of a .dockerignore file for projects that don't already have one, saving you time and reducing image bloat. By excluding common unnecessary files—like .git, node_modules, or local configs—it helps keep your builds clean, fast, and secure right from the start, without needing manual setup.
Networking / Reduce costs: We have implemented private networks, as mentioned in the official Compose specification. We have also reduced costs by eliminating the need for a pricy NAT Gateway in "development mode" deployments!
In March, we had an incredible evening at the AWS Gen AI Loft in San Francisco! Our CTO and Co-founder Lionello Lunesu demoed how Defang makes deploying secure, scalable, production-ready containerized applications on AWS effortless. Check out the demo here!
We also kicked off the Defang Campus Advocate Program, bringing together advocates from around the world. After launching the program in February, it was amazing to see the energy and momentum already building on campuses world-wide. Just as one example, check out this post from one of the students who attended a session hosted by our Campus Advocate Swapnendu Banerjee and then went on to deploy his project with Defang. This is what we live for!
We wrapped up the month with our monthly Coffee Chat, featuring the latest Defang updates, live demos, and a conversation on vibe coding. Thanks to everyone who joined. The next one is on April 30. Save your spot here.
As always, we appreciate your feedback and are committed to making Defang even better. Deploy any app to any cloud with a single command. Go build something awesome!